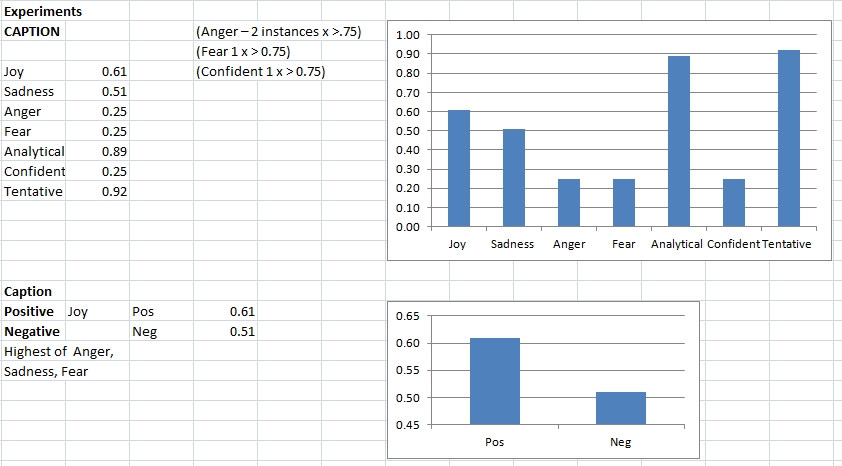
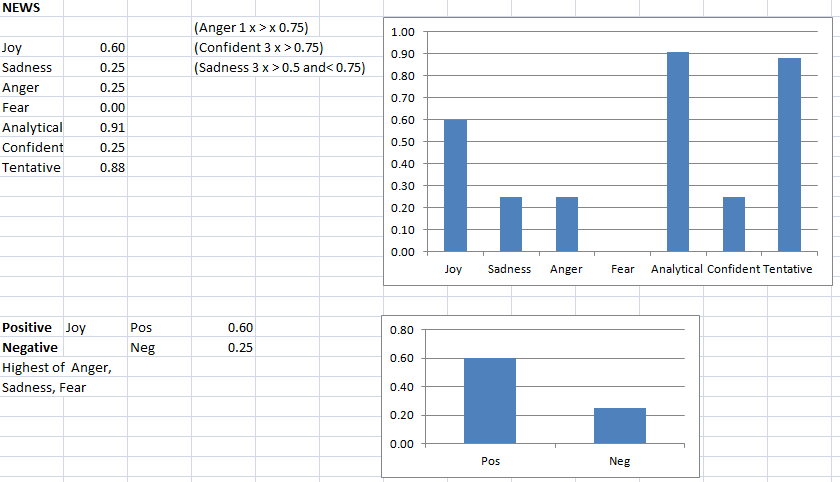
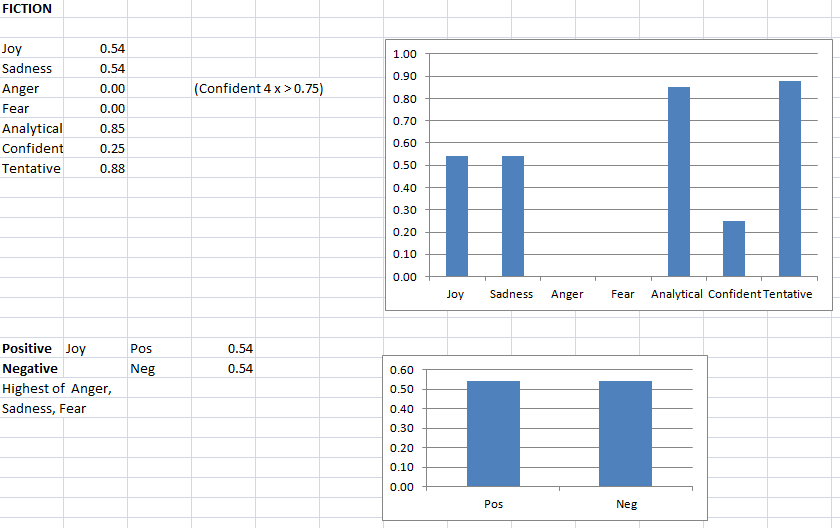
I examined in August 2020 research (UAL London see credits) what happens when writers use a computer text generator to write articles, giving them only an image prompt. There is a summary of the Study in the Index.
Go to Index of AI research
Fake News – (or ‘fake news’) what do real writers think about it?
Summary
- People who have a lower general opinion of text generation, and lower wordcounts for feedback, don’t think text generation is relevant to ‘fake news’.
The converse, that people who are more engaged with text generation (more feedback, more positive) can see that it is more related to fake text generation.
So, if people are educated on the topic, they will realise there is a relationship between advances in computer text simulation and fake news.
Definition of fake news
Even defining fake news is not that simple, since if you look for examples in the USA, or Syria, or anywhere else, both sides accuse the other of using it. Depends on there being no consensus as Barak Obama mentioned recently. See the bottom of the blog for some discussion.
Fake News
One of the feedback questions in the Study was about whether computer AI text generation was relevant to ‘fake news’ (false content for spam, propaganda etc.).
Q6-2: If you have heard of ‘fake news’ do you think this is relevant?
This had neutral phrasing in order not to influence replies. It did not say ‘text generator can make fake news’ as this presupposes a technical knowledge that might not be present, even after doing the experiments. Given the sometimes bizarre output of the generator, it might affect replies too specifically.
18 of the 82 respondents – 22% – replied to the question. It was the last question after a long session so perhaps some fatigue had set in. It was also a question not specifically to do with the experiment. About a quarter is still quite a high response rate.
Analysis of responses
I will be examining the actual text answers in another blog. This just looks at some basic relationships.
Several comparisons of the data were calculated and some are worth discussing here (the others are in reference material).
Comparing answer word count with positive – negative ratings:
The actual Q6 answer text was assessed for Positive – Neutral – Negative response to the ‘relevant to fake news’ question.
For instance, the text answer ‘No’ was 2 for negative, word count 1. ‘I stay out of these type debates.’ Is 1 for neutral, word count 7.
This was quite easy to do. I did not use a computer sentiment analyser as the samples were too small. Anything a bit ambiguous or with conflicting statements was rated Neutral.
Pos – neg is 0 (positive), 1 (neutral), 2 (negative) – these are scaled up so can be seen against the word count values. So low red columns are positive (yes, relevant to ‘fake news’) , high red is negative (not relevant to ‘fake news’). This is an ordinal scale.
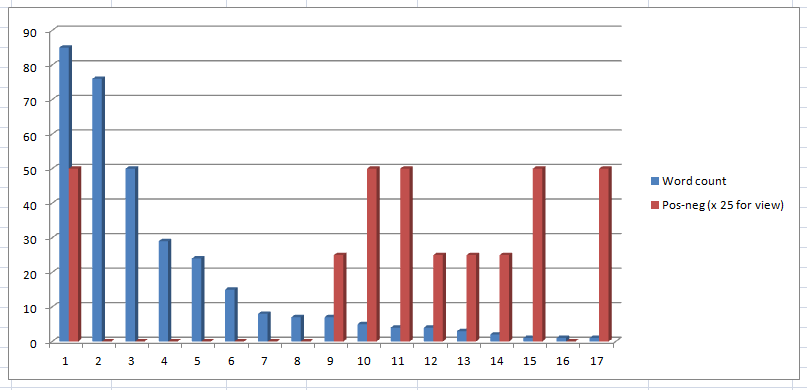
Above: Pos-neg is zero for positive for ‘relevance’ to ‘fake news’. The red Pos-neg 0-1-2 value is scaled to make it easier to see. So a tall red line means negative for relevance to fake news. (There is a discussion of different statistical calculations in a forthcoming blog. The tests used in the study are Mann Whitney U, T-Tests, ANOVAS, and Pearsons, along with various bar charts and boxplots.)
At first glance this shows that higher answer word counts are associated with positive for ‘relevance to fake news’.
Low word counts are associated with negative for ‘relevance to fake news’.
There is only one negative out of the top half of the responses (1-9 on the chart above, 2-8 are pos=0).
The highest word count (column 1 on chart) was from an answer that discussed an actual example of real ‘fake news’, or propaganda in the Syrian War, so was a longer than usual negative response. It could be an outlier. After ruminating they decided it was too hard for a text generator to do, writing ‘news of any kind has to be created by humans…’ which is a value judgement (humans are best).
Statistics
Mann Whitney U test
The z-score is 4.25539. The p-value is < .00001. The result is significant at p < .05.
- People who used the least words thought text generation was less relevant to ‘fake news’.
- People who used more words in their answer thought it was more relevant to ‘fake news’.
Discussion
In other work, computer Sentiment Analysis revealed that all feedback answers had high scores for ‘Tentative’ and very low (no score) for ‘Confidence’. These results could be because of a general lack of experience of text generation (only 11% had previous experience).
There is a forthcoming blog on the Sentiment Analysis, there is already a blog on Sentiment Emotions (Joy etc.).
When making a positive claim (‘there is relevance’) with no ‘Confidence’ and feeling very ‘Tentative’, discursive answers are to be expected.
In the positive answers, the relevance of ‘fake news’ produced more discussion (‘Yes, and here’s why…’). This could be because the respondent felt it was relevant, but had little or no confidence in their feelings and supplied a tentative, more wordy, answer.
Whereas with a negative response, text generation is not relevant to ‘fake news’, and can be easily dismissed (‘No’ – 1 word).
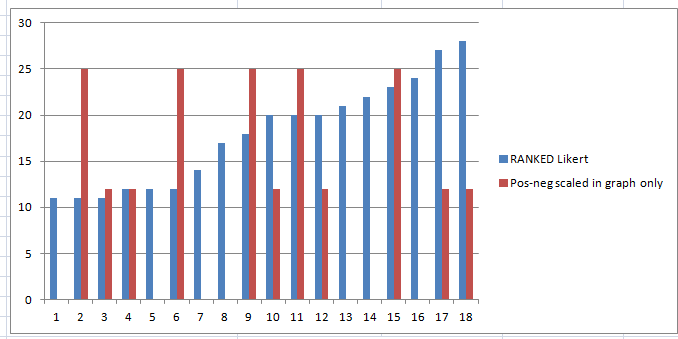
Ranked Likert scores over the Study vs Pos-neg
Mann-Whitney U Test
The z-score is 5.10963. The p-value is < .00001. The result is significant at p < .05.
This is not visually very clear until you sum the raw (before scaling for graph) scores from columns 1-8 (6) and 2-18 (10).
- This shows that lower Likert scores (which means positive response to experiments and later questions) relates to lower Pos-neg scores (which means positive relevance to ‘fake news’). This is what would be expected.
- People who have a lower general opinion of text generation, don’t think text generation is relevant to ‘fake news’ (and possibly anything else of practical use).
Amateur – Professional
People were asked to select Amateur/Professional (or both, scored as Pro) next to Occupations. Most people had more than one occupation (Poet and Journalist etc.) so it is not a fixed job allocation, but provides an indication that the writer either is or would like to be paid for at least some of their work.
This did not provide any significance at the ‘fake news’; response level.
There is a forthcoming blog on Amateur/Professional differences.
Comments
Is there a connection between text generation and ‘fake news’?
1/ Human pride: anthropocentrism: people that dismiss the use of text generation and its relevance to ‘fake news’, say ‘news of any kind has to be created by humans…’.
2/ The idea that a computer could not be used to write news, ‘fake’ or otherwise, might be due to the rather random output of the mid-level (GPT-2) text generator used in the Study. People might think it is producing readable nonsense, and brusquely dismiss any practical uses. This is shown in the relation between overall negative scores (Likerts) and low relevance for ‘fake news’.
3/ Perhaps dismissal of a text generation tool in regard to ‘fake news’ is indicative of not believing there is ‘fake news’ (or that it is not a problem), shown in the low word counts of their short negative responses. Further research required.
Notes
1/ Answers
If you have heard of ‘fake news’ do you think this is relevant?
Replies went from the four shortest (1 or 2 words)
If you have heard of ‘fake news’ do you think this is relevant?
No (scored 2, neg)
No! (scored 2, neg)
Sure (scored 0, pos)
Not really (scored 2, neg)
to the four longest (89, 85, 76, 50 words; 2,2,0,0)
If you have heard of ‘fake news’ do you think this is relevant?
“Unless the AI used to generate the text is extremely advanced, I think any news text generated wouldn’t be very effective — fake or otherwise. I think, at this point in our technology, news of any kind has to be created by humans to effectively educate, manipulate, or make humans react like chickens with their [thinking] heads cut off. If a text generator is going to be effective at writing propaganda, it’s skills are going to have to increase a heck of a lot. Ask again in five years.” (scored 2, neg)
“Very difficult to unpack – particularly as the different sides each claim the other side is distributing fake news. Having followed the Syrian War closely, I know for a fact our major news channels spouted fake news. Could something like this be used in social media to reply with biased opinions? Perhaps, but the existing troll farms used by all sides are often quite sophisticated, with the least sophisticated being the least effective. So, this type of low level autogeneration would not be very effective.” (scored 2, neg)
“Oh yes! Too many people are not analyzing the sources. Maybe that is too big a job or most and maybe many do not know to do this. My son repeats this claptrap to me as if it is gospel and he does not understand me when I tell him that his source is untrustworthy. He thinks if he hears something from dozens of people it must be true. Mass media is powerful in that way. “ (scored 0, pos)
“It is an enabler of fake news (eg allowing much faster fake news to be created – especially if fed in the analytics re effectiveness of dissemination etc.) but could also make REAL news reporting more efficient and effective especially if it supports optimum use of human vs AI input.” (scored 0, pos)
The text samples were too small to use computer sentiment analysis, so I scored the replies myself (human accuracy is still the best for nuanced material). Much training data for sentiment analysis is annotated by humans before use. See references.
Positive – is relevant – 0
Neutral – don’t know, don’t care or not sure – 1
Negative – is not relevant (not good enough, unsuitable, not required) – 2
How done
Sum Likerts (inverting the sixth Q (Q3/of 6 at end), the third after the 3 experiments), rank, then compare to texts, which are scored
0 pos (relevant to fake news), 1 neutral, 2 neg (not relevant to fake news).
Note: Q3/6: Do you feel that you have used somebody else’s work?
This Likert scored the other way, ie, the first option (score 1) was the most negative (is somebody else’s, ie plagiarism).
So in the calculations this score was inverted (1 become 5 etc.).
Other Calculations
1/
Overall Likert score (low positive affect) vs Fake Pos-neg relevant – neutral – not relevant
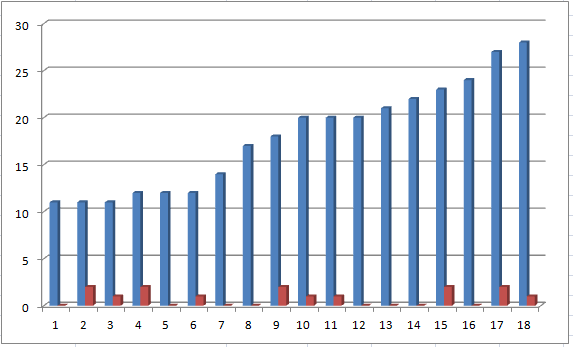
There is no significance to this relationship.
2/
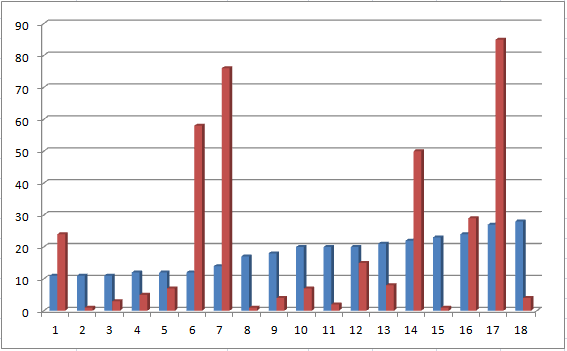
vs. word count vs Fake news Pos-neg relevant – neutral – not relevant
References
Sentiment analysis papers:
https://www.kdnuggets.com/2020/06/5-essential-papers-sentiment-analysis.html
What is fake news?
Important researcher: Xinyi Zhou
These are the most recent papers on fake news:
A Survey of Fake News:
https://dl.acm.org/doi/10.1145/3395046
Fake News Early Detection:
https://dl.acm.org/doi/10.1145/3377478
Generally, fake news is false or distorted information used as propaganda for immediate or long-term political gain. This definition separates it from advertising, which has similar approaches but is for brand promotion rather than life or death matters. False can be anything from an opinion to a website which appears to be proper news but is actually run to spread false information.
This has led to ‘reality checks’ where claims are checked against reality (which still exists) but the problem is that fake news spreads very quickly (because it appeals to the emotions, often fear or hate) while corrections take time to process and are very dull, so hardly anyone reads them, as they have no emotional content. Certainly the people that react to the fake news (if it is proven so) have moved on already, to the next item.