
Index for AI research blogs / Geoff Davis UAL CCI London
I am doing research into how people use computer art and text generation, in a field generally known as “AI” or artificial intelligence, at UAL University of London. My research supervisor is Professor Mick Grierson (see credits at bottom). This finished 2025 – dissertation to be published soon.
My dissertation is due for publication this year. It was based on the two research projects below, known as “Mood Bias” and “Pro Writers”.
See also AI Creative Anthology #aicreativeanthology #aiart #generativeai #aiarts #aiwriting #aifiction #aipoetry #artistgeoffdavis
“Mood Bias” AI research – 2022-2024
Four mixed media experiments to test how different consumer AI ‘chat’ and image systems used a particular ‘mood’ in their user experience. Does this overly manipulate people? Experiments were:
- One Word Prompt (humanist counselling)
- A Visit From ChatGPT (narrative continuation)
- ChatGPT On The Couch (psychoanalysis)
- Robot Rorschach (image labelling of ‘robot suitable’ test cards)





AI Mood Bias research Geoff Davis UAL London
#artistgeoffdavis @aicreativeanthology @microartsgroup
AI Mood Bias
Talks: This was presented at EVA London, 2023, and a summary was presented at the Franke Foundation Generative Art summit Berlin, 2024.

Please visit Geoff Davis Mood Bias & Happy Ending Syndrome page
Pro Writers and AI Tests – 2019-2021
This is now online at UAL Research:
https://ualresearchonline.arts.ac.uk/id/eprint/18621/
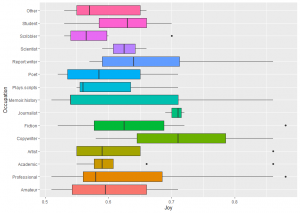
86 professional writers conducted caption, short, and long form AI writing tests.
Summer 2020, using my app with Fabrice Bellard’s Text Synth, see Story Live with GPT-J 6B, NeoX 20B etc.
What happens when writers use a computer text generator to help write various types of articles? What are their experiences when doing this hybrid activity? This is open-ended (no hypothesis, grounded research) and multi-modal.
Apart from the practicalities of using a text generator, I also addressed plagiarism and ‘fake news’ (see below), and examined how the writer’s occupation (poet, copywriter) affected response.
I previously programmed story generators on micro computers. The first computer poems were generated in 1953. So literature and computing has a long history. My ‘Story Generator’ has been exhibited mutliple times 1985-2024 and was released by Micro Arts (my computer art forum) on data cassette and also Prestel teletext in 1985. Visit Micro Arts: Story Generator

Study 1 – August 2020
OpenAI’s GPT-2 was used for research into how professional writers use text generation.
Results
The study had three text generation and editing experiments, and included many feedback questions.
Nine out of ten of these writers (89%) had never used a text generator before. It is easy when working in the computer domain to assume everyone knows about technological advances, but they do not, even in their own field.
The system I devised (with Fabrice Bellard) for the study is now live for everyone at Story Live (new page).
Future work
I am now working with OpenAI’s latest GPT-3, and the OS systems like GPT-J and NeoX.
Links
The report will be published soon. Some have been on the Blog but these are now private.
2022
I am editing an anthology of creative writing with AI – a loose concept. This will be published later in the year by Leopard Print Publishing with Story Software Ltd UK.
The study had writing experiments which used an ambiguous image prompt (see below).

FAKE NEWS
For more information on ‘fake news’ research
Please visit Xinyi Zhou‘s work here.
These are the most recent papers on fake news:
https://dl.acm.org/doi/10.1145/3395046
https://dl.acm.org/doi/10.1145/3377478
AI Poetry Workshop

This was conducted in August 2020 using GPT-2. The results were not published.
For details, see AI Poetry Workshop.
Research Credits
These studies were devised, and the study site programmed, by Geoff Davis for post-graduate research at University of London UAL CCI 2019-2020. Research supervisor is Professor Mick Grierson.
Text Synth
Now live for everyone at Story Live (new page) (depreciated).
Geoff Davis:
A publicly available text generator was used in the study experiments, as this is the sort of system people might use outside of the study.
It was also not practical to recreate (program, train, fine-tune, host) a large scale text generation system for this usability pre-study.
Fabrice Bellard, coder of Text Synth:
Text Synth is build using the GPT-2 language model released by Google OpenAI. It is a neural network of 1.5 billion parameters based on the Transformer architecture.
GPT-2 was trained to predict the next word on a large database of 40 GB of internet texts. Thanks to myriad web writers for the training data and OpenAI for providing their GPT-2 model.
Permission was granted to use Text Synth in the study by Fabrice Bellard July 7 2020.
See bellard.org
GPT-2
Visit OpenAI’s blog for more information on Google’s OpenAI text generation.
Image prompt man and dog photo
The image is from public sources under free license, it is an old image. See Man and Dog blog.
Copyright
All material on this website is copyright Geoff Davis London 2021.